LiteBench
Benchmark any LLM. Compare everything.
A desktop LLM benchmark studio. Run a 12-test Agent Suite where models drive 14 real tools — browser, web search, code sandbox, file I/O — then score them with a multi-criteria engine, rank them head-to-head with ELO, and compare side-by-side across 12 chart types. Per-model harness profiles tune each model fairly; SSE streaming shows every token live. Works with any OpenAI-compatible endpoint — local or cloud.
What it does
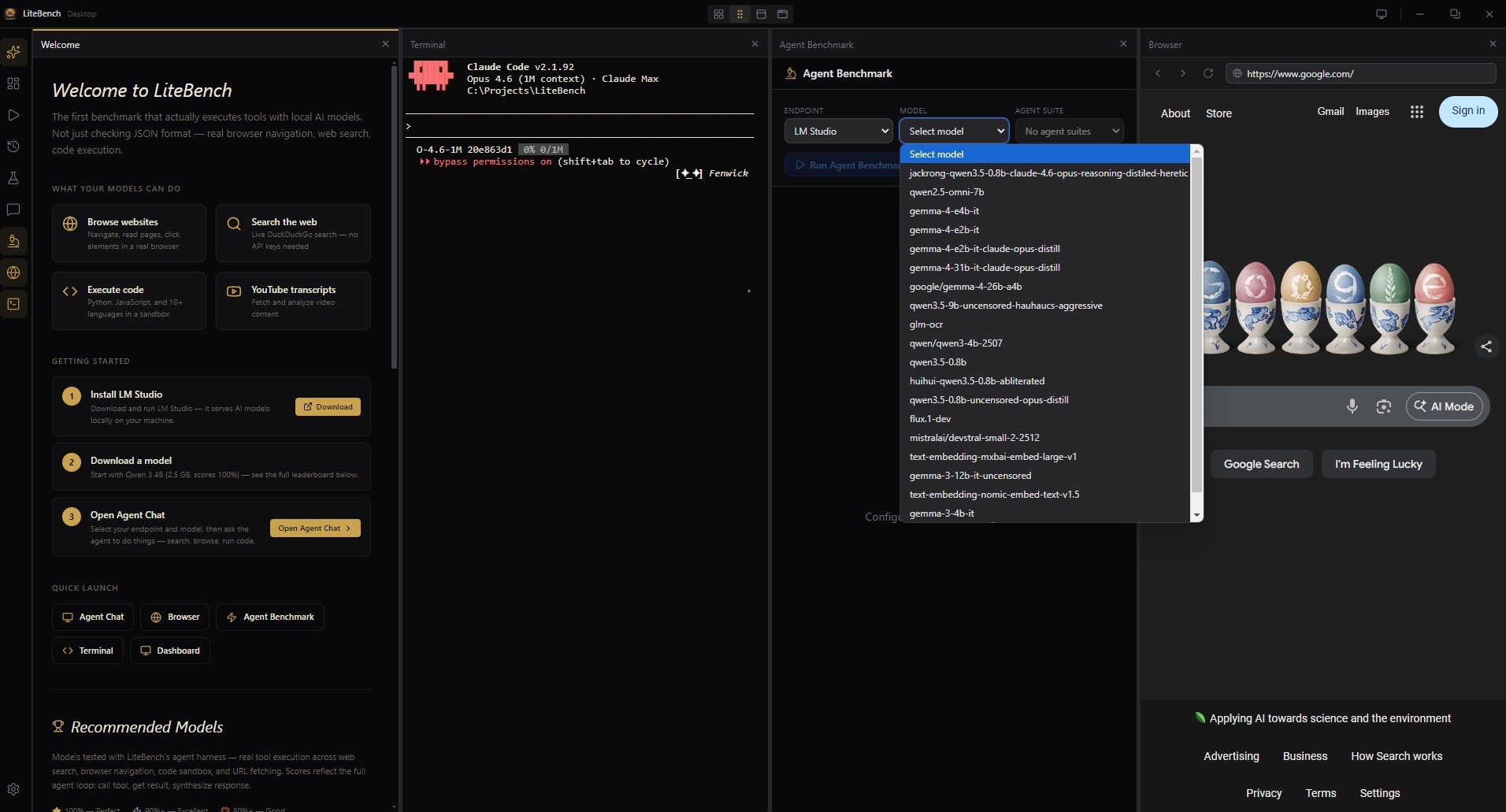
12-Test Agent Suite
Models drive 14 real tools — browser, web search, code sandbox, file I/O, YouTube — through multi-step tasks. Scored on tool-call accuracy and observable behavior, not multiple-choice.
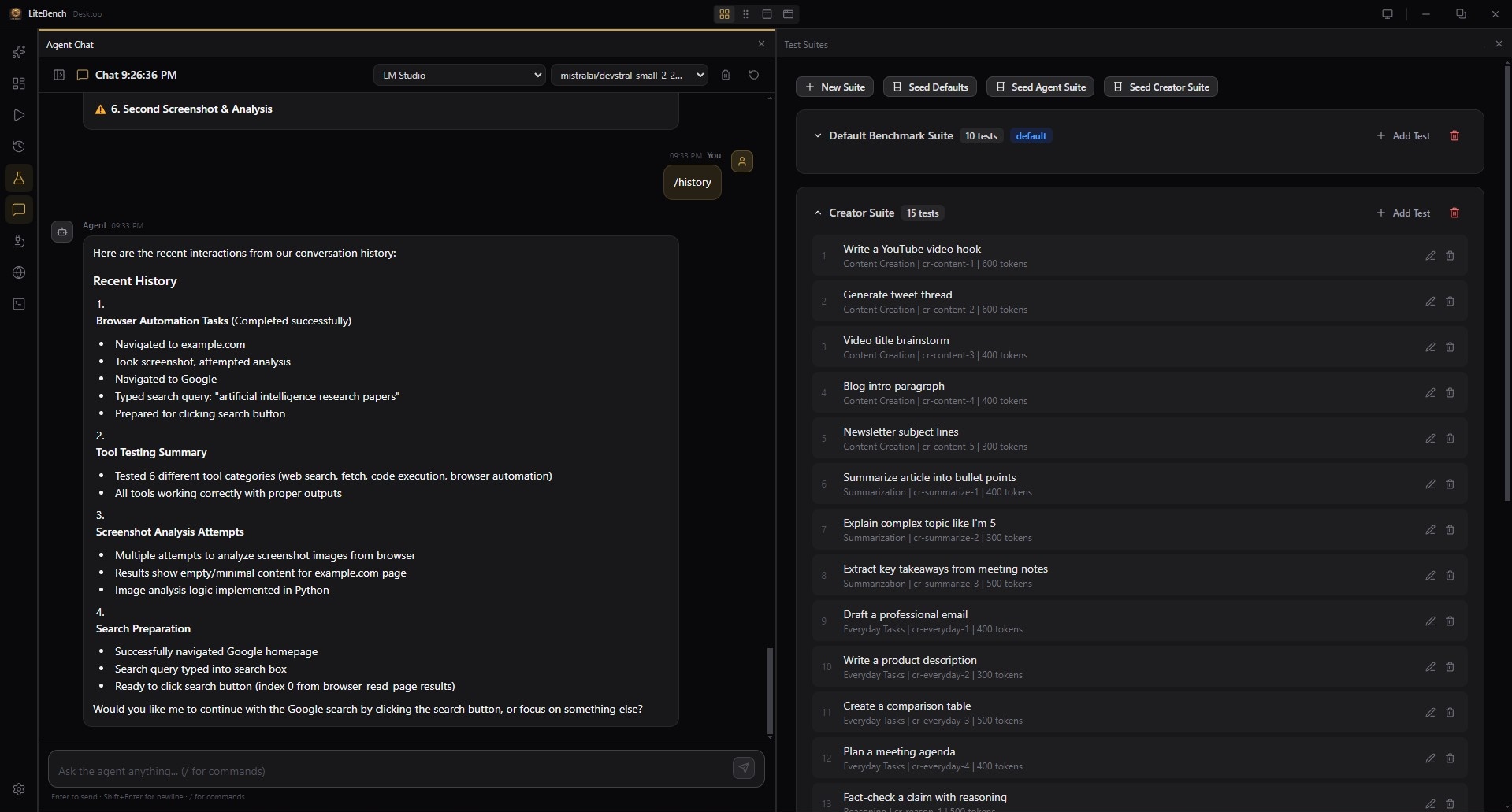
Head-to-Head + ELO
Run any models against each other on the same tasks and rank them with an ELO leaderboard. Stop guessing which model — or which quant — to trust.
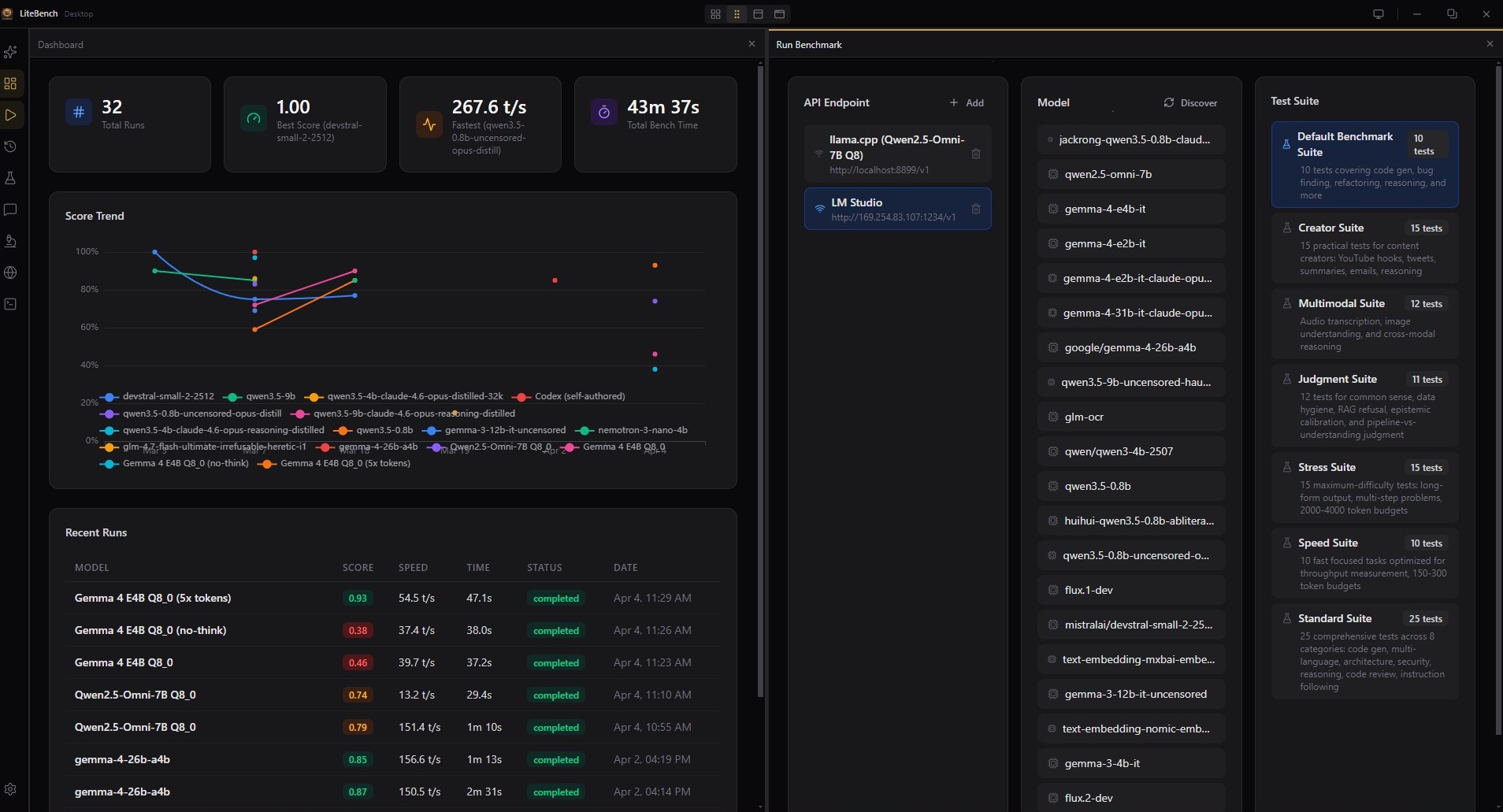
Dashboard & Score Trends
Score trends, recent runs, and benchmark configuration at a glance — with per-model harness profiles that tune each model fairly.
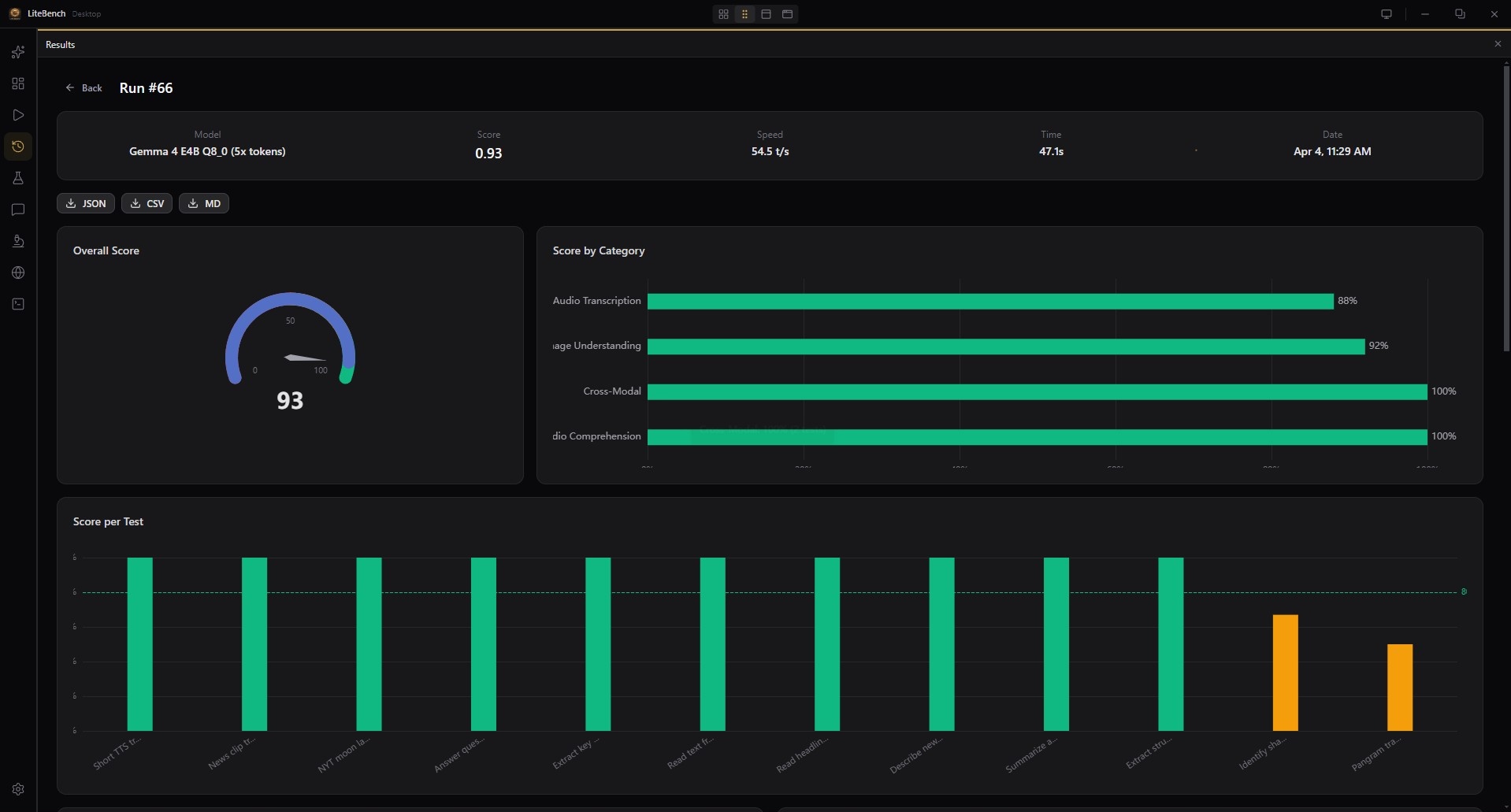
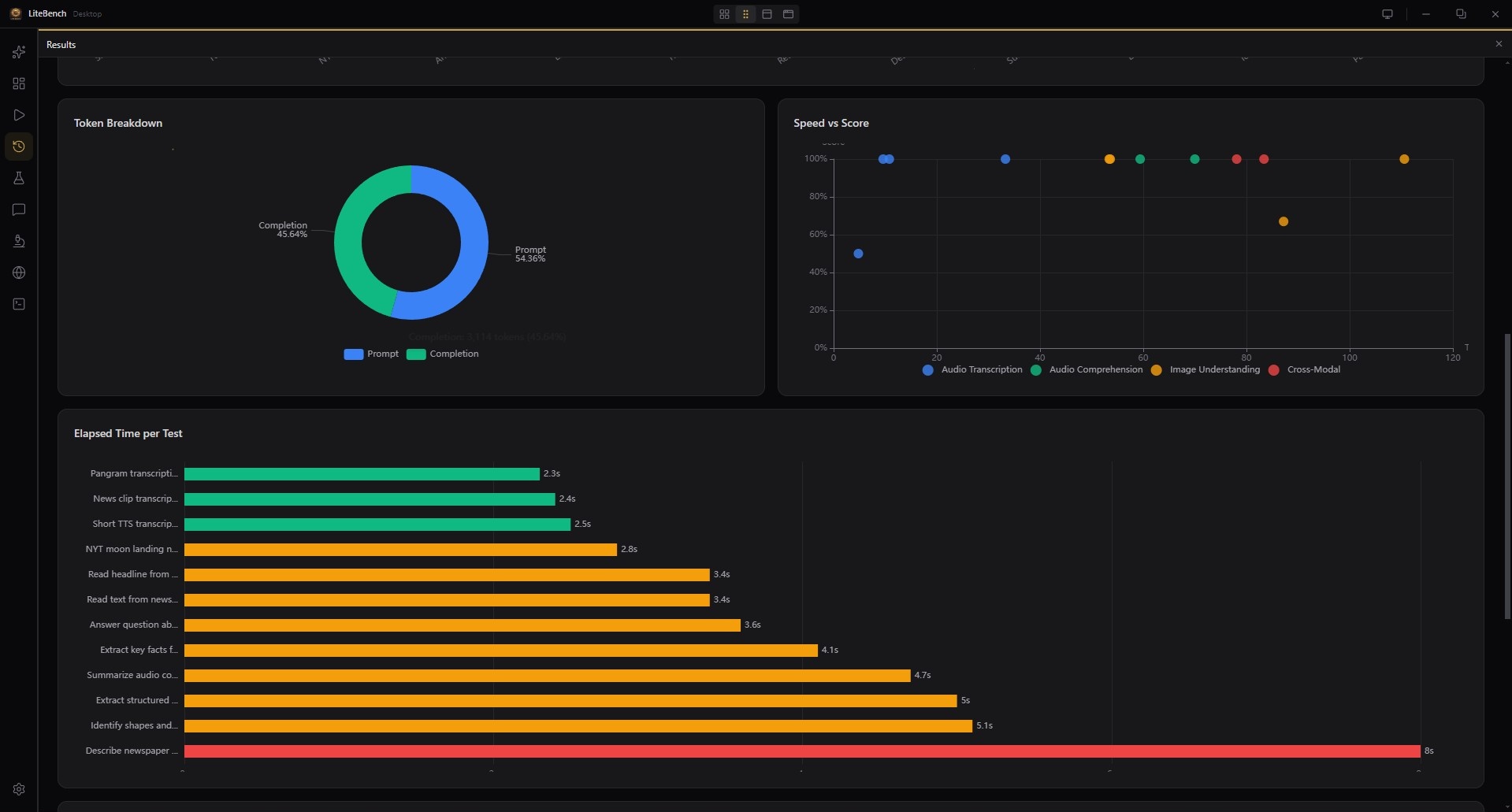
12 Chart Types
Token breakdown, speed-vs-score scatter, elapsed-time, category radar — visualize every dimension of a run, with SSE streaming live as it happens.
Why LiteBench?
The only desktop benchmark studio that runs agentic tool-use tasks head-to-head with ELO ranking — not multiple-choice quizzes — so you stop guessing which model, or which quant, to trust.
See it in action
Demo video coming soon